An Overview of Keycloak’s Built-in Providers
Keycloak has the capability to fetch and retain data concerning authenticated users through either the internal storage backends or “user storage providers”:
LDAP federation: This provider supports connecting to a directory service using the Lighweight Directory Access Protocol version 3 [3] with “simple bind authentication”, i.e. Keycloak has knowledge of a service account name and a password text credential to connect to the LDAP service. Communication can be safeguarded by implementing TLS with server authentication. If configured, Kerberos [2] authentication can be negotiated between user and directory service.
Kerberos: If Keycloak is linked with a Kerberos realm, this provider facilitates the authentication negotiation of user principals. Authenticated users are then recognized as identities by Keycloak, effectively making the Kerberos realm an identity source.
If Keycloak is configured as a client application on a remote IdP, then the identities provided by the remote IdP can be accepted by Keycloak; the Keycloak IP becomes a “broker” for these identities. The protocols OpenID Connect version 1.0 [4] and OASIS SAML version 2.0 [5] are available for this integration.
Through leveraging these integrations, the following capabilities are enabled:
Remote identities are recognized as valid in Keycloak, allowing for user sessions to be initiated using the username associated with the external identity..
During the authentication process, remote systems can handle at least one authentication factor. In LDAP federations, this might entail password credential verification and/or establishing Kerberos sessions. In identity federations, authentication is wholly managed by the remote IdP when brokering.
Yet, Keycloak lacks a built-in solution for managing identity data stored within an existing relational database.
About the Custom Provider
Below, we showcase an example implementation utilizing Keycloak’s “User SPI” extension interface [17], which connects a relational database containing users (optionally with Keycloak role associations) to a Keycloak realm.
The custom provider has been published in source code form on GitHub[15] under the Apache License Version 2.0. It’s important to note that this software is specifically designed for testing and experimentation purposes. Therefore, it is provided “as is” without any warranty of any kind.
Goals
Our implementation aimed to achieve the following objectives:
Serve as a reference implementation for assessing best practices and potential challenges in integrating databases with Keycloak.
Notice release changes in Keycloak that may disrupt the implementation.
Identify and report any issues encountered in the Keycloak software and/or documentation to the Keycloak development team, and contribute to resolving them whenever feasible and relevant.
Design and Implementation
Determining the Requirements
As opposed to publicly defined protocols such as LDAP version 3 or Kerberos version 5 which offer formal specifications of data structures and network protocols, accessing a relational database can occur through various methods, with only limited standardization available.
An industry-standard addressing uniform access to relational databases is “Java Database Connectivity” (JDBC, [6]). Additionally, solutions exist for organizing persistent objects in a database, such as the “Hibernate ORM” framework [7]. However, it’s important to note that alternative solutions also exist for the Java programming environment.
In summary, there is no universally recognized “single, best practice” for storing identities in a relational database. Consequently, any implementation can only aim to handle specific configurations of relational storage, rather than addressing the entire task of “integrating identity stores residing in relational databases” as a whole.
The outlined setup in this example implementation is detailed as follows:
- A single external relational database contains a single table storing one identity per row.
- A JDBC driver compatible with the database is available for use within a Keycloak user SPI.
Regarding password attributes of identities, further assumptions are made:
- User passwords are stored within a column of the identity table as SHA-512 hashes, formatted in a manner compatible with the standard C library “crypt” function.
Modelling the Persistence Database
User identities are intended to be stored in a table format, with each identity occupying one row. This table would typically include columns for ID, username, password hash, and additional profile information such as first name, last name, and email address.
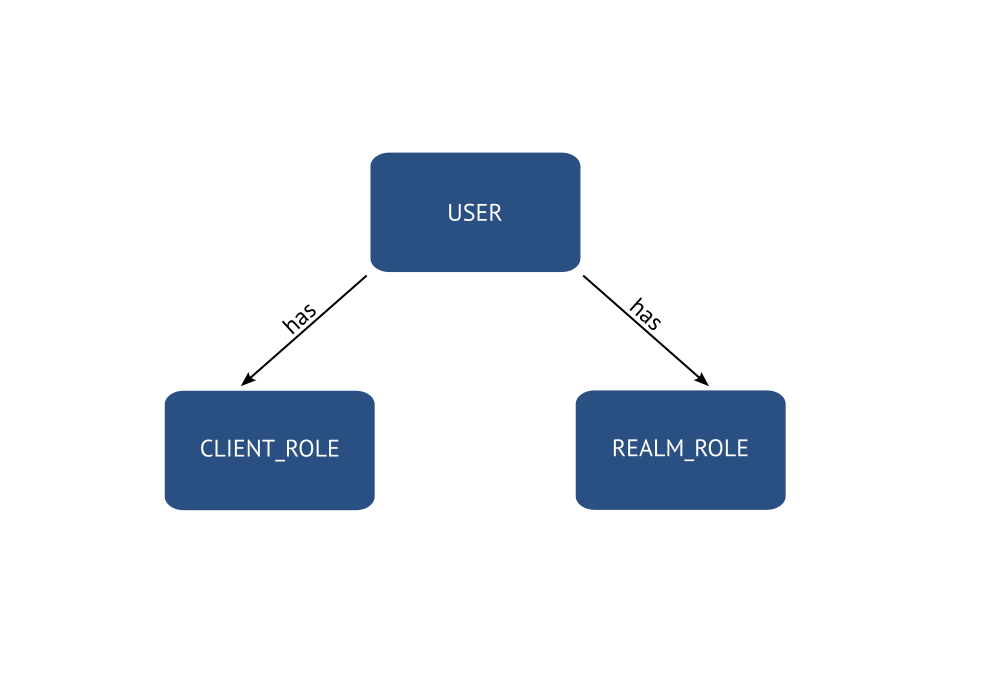
Multiple “realm roles” and “client roles”, identified by name, can be assigned to a user.
Client roles are stored in a dedicated table; they are specified by a “client ID” and a “role name”.
Realm roles are also stored in a dedicated table; they are specified by the “role name”.
Data Flow Considerations
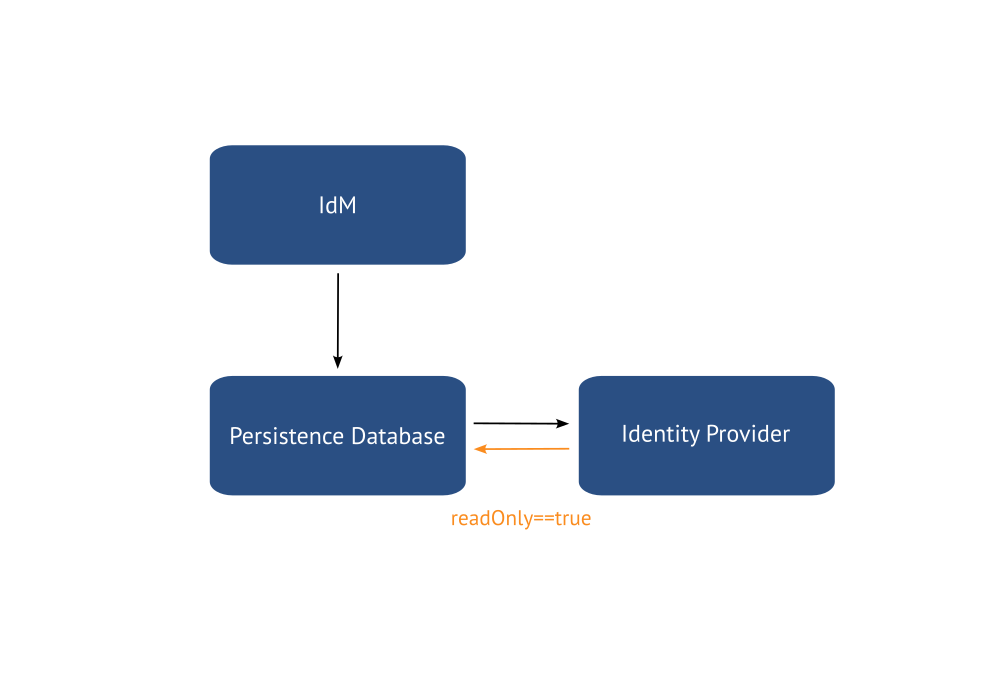
The custom provider is designed to consider the datasource as authoritative; information about users and their role mappings is expected to be provided to the datasource from an identity management system.
The provider shall feature a boolean configuration setting “readOnly”, by default set to true, disallowing any changes from the Keycloak side to data that originates from the “user-storage-test” federation (i.e. the set of users or any of their attributes and role associations).
Data Consistency Considerations
The custom provider shall perform no translation of client IDs or role names from the database to their repspective identifiers in the Keycloak realm. Identical client IDs and role names are expected to pre-exist in the Keycloak realm to which the storage is attached.
The provider should incorporate a logging mechanism to issue warning messages when clients and roles found in the database are missing in the Keycloak realm.
Keycloak Datasources as ORM Solution
Keycloak uses the Quarkus Java Framework [8], with the Keycloak application database defined as a Quarkus “datasource”. Additional databases can be defined as additional datasources.
Assuming that a JDBC driver supported by the Hibernate framework for object-relational mapping [7] is available for a datasource, Keycloak documentation and “quickstart” code examples [9], [17] demonstrate the usage of the Jakarta Persistence API (JPA) for object persistence.
By default, Keycloak uses the Jakarta Transaction API (JTA) and X/Open XA [10] to coordinate transactions across multiple datasources.
Our implementation of the custom provider adopts these technologies.
Results of the Evaluation
Issues with the Persistence System
The persistence subsystem Jakarta Persistence API (JPA) allows for object-to-object relations to be mapped to database structures. This mostly happens implicitly (a Java class property “email” becomes a column of the same name in the associated database table); specific information (for example which table to store the Java class instances in) can be given using Java code annotations.
Throughout our implementation, we discovered that the hierarchy of Keycloak classes and interfaces, coupled with certain intrinsic and inadequately documented Keycloak behaviors, complicates the process of working with persistence.
For instance, understanding the differentiation between an “attribute” and a “property” of a user within the Keycloak framework can be challenging. Keycloak imposes distinct code requirements and intrinsic behaviors on certain properties and attributes. While developing the example provider “user-storage-test,” we discovered that the “password” property required a different interface compared to other properties. Additionally, during testing of the provider, we found that the “emailVerified” property (which is not persisted in our implementation’s database) was treated as an attribute.
Hibernate provides various tuning capabilities that are relevant for production environments. However, the Quarkus properties mechanism imposes restrictions on the configuration settings available.
For instance, it’s preferable to store the JDBC URL of the datasource in a properties file rather than in Java code or the persistence.xml file. This ensures that JDBC connection information, including database access secrets, is not hardcoded in the provider JAR. However, this approach necessitates explicitly stating the Hibernate database dialect in the persistence.xml to avoid compile-time errors. Consequently, this ties the provider JAR to a specific database driver and type.
Overcoming this limitation typically involves significant development effort. For example, one project [16] found it necessary to re-implement JPA connection management for their user storage SPI.
Unclear Caching Behavior
The meaning and effective impact of the different available caching policies (“DEFAULT”, “NONE” and others) for a user storage provider are not clearly explained in the documentation (at least not from the Keycloak Server Development Guide, subsection “Cache policies”, [13]).
Which Datastore is Authoritative?
When operating an additional datasource as user federation, user creation in the Keycloak realm defaults to the new external datasource, and neither the API endpoints nor the administration user interface offer possibilities to choose which federation a new user should be created in.
Effectively, this means that our implementation, when activated, performs a “takeover” of the user storage. If a user is created within Keycloak, the platform attempts to insert a row into the “users” table. However, if the custom provider instance is set to read-only mode, this operation is not feasible, rendering the creation of users within the Keycloak realm effectively impossible.
Regarding this matter, specifying a custom provider as “read only” — meaning it does not execute any writes to the data source — is not documented as a configuration setting, class property, or pattern. Neither the Keycloak API, nor Quarkus, nor JPA, nor Hibernate provides guidance on how to achieve this. The way specific built-in providers implement this behavior - notably the LDAP provider, which delegates to either a “regular” or a “read-only” user adapter class based on a provider-specific configuration setting, is not straightforward for a custom provider adhering to the User SPI documentation and/or the JPA provider “quickstart” example.
Also, declaring certain attributes “read only” is not a documented procedure while being mandated by the server administration documentation in no uncertain terms [14].
The documentation for Keycloak’s User SPI [17] and its REST API [18] do not explicitly address topics related to datasource authority and data flow. The closest approach is an outline of what is called the “import implementation strategy” [19] from which can be quoted:
With the import approach, you have to keep local Keycloak storage and external storage in sync. The User Storage SPI has capability interfaces that you can implement to support synchronization, but this can quickly become painful and messy.
We found this phrasing to be discouraging and decided not to pursue the “import approach” any further.
Stability Issues
Incorporating an additional data source for user storage creates a close dependency between the stability of the Keycloak instance and that of the external database system. It necessitates the use of JTA (Java Transaction API) to manage transactions across multiple relational database connections. This leads to additional operational challenges.
During testing of the custom provider, Keycloak became unresponsive multiple times when certain database modifications occured. The observed issue was that stopping Keycloak was only possible by sending a “SIGKILL” UNIX signal to the Java runtime process. Consequently, this action resulted in stale references in the JTA transaction log upon the next startup of Keycloak, as indicated by XA-related log error messages. Resolving this issue necessitated manual analysis of the log file and deletion of entries in Keycloak’s data directory.
In the event of such an incident occurring in a production environment, it could have led to unplanned maintenance due to the absence of clear vendor documentation and multiple service interruptions.
A valuable lesson we learned was the importance of careful planning and execution when implementing changes to the datasource, such as modifications to connectivity, schema, or data.
However, we encountered challenges due to gaps in the available documentation, particularly in areas such as caching, ORM intricacies, and configuration related to transaction management. These gaps made it difficult to accurately estimate the impact of such changes. We observed that efforts within the Keycloak project [11] have been directed towards clarifying the configuration of XA behavior. This effort is evident in the context of enabling the use of the Cockroach database [12] as a datasource.
Other Known Limitations
The custom storage provider currently exhibits certain limitations, which could potentially be alleviated through further development efforts:
If the “user-storage-test” provider is activated in a realm with configuration option “readOnly” set to false, all users that are created using the Keycloak admin console or REST API are getting created in that federation. There appears no way to choose the federation when creating users in Keycloak.
If the “user-storage-test” provider is activated in a realm with configuration option “readOnly” set to true, user creation in the Keycloak realm fails with an unspecified error.
It is currently not possible to persist role mappings defined in the Keycloak realm back to the database.
Conclusions
The ongoing expense, commonly referred to as “technical debt,” associated with maintaining a custom provider should not be underestimated. Utilizing Keycloak with such an extension to the built-in user storage may necessitate recovery procedures that fall beyond the purview of the vendor’s documentation.
We suggest that some cleanup and clarification that was planned as Keycloak’s new “Map Storage” ([21], see also [23] for an example for such cleanup) should find their way into the software even though the overarching effort has officially been discontinued [22]. Any effort leading to that direction can only be encouraged.
The importance of clear datasource authority and flow of data in an identity provider can not be overstated; declaring a custom datasource “read-only” should be an obvious option of a datasource and/or a documented method of every user storage provider.
Also, we encourage a clearer stance and more streamlined management of “attributes” vs. “properties” of users throughout the application, user model and related SPIs. In the broader domain of identity management and similar products, user identities typically possess “attributes,” and there isn’t a distinction where some attributes are treated differently as “properties” (for reference, see [24],[25]).
Links and References
Note: All external URLs below have been accessed on Feb. 4th 2024.
- [1] https://www.keycloak.org, Keycloak project homepage.
- [2] https://datatracker.ietf.org/doc/html/rfc4120, Internet Engineering Taskforce. Request for Comments (RFC) 4120 “The Kerberos Network Authentication Service (V5)”.
- [3] https://datatracker.ietf.org/doc/html/rfc4511, Internet Engineering Taskforce. Request for Comments (RFC) 4511 “Lightweight Directory Access Protocol (LDAP): The Protocol”.
- [4] https://openid.net/specs/openid-connect-core-1_0.html, https://openid.net/specs/openid-connect-core-1_0.html.
- [5] https://wiki.oasis-open.org/security/FrontPage, OASIS SAML Wiki Front Page.
- [6] https://docs.oracle.com/javase/8/docs/technotes/guides/jdbc/, Oracle Inc. Java SE 8 Documentation. Java JDBC API.
- [7] https://hibernate.org/orm/, Hibernate ORM framework homepage.
- [8] https://quarkus.io/, Quarkus framework project homepage.
- [9] https://github.com/keycloak/keycloak-quickstarts/tree/latest/extension/user-storage-jpa, “Keycloak quickstarts” Github repository, subdirectory for JPA user storage example.
- [10] https://pubs.opengroup.org/onlinepubs/009680699/toc.pdf, The Open Group Ltd. Technical Standard. Distributed Transaction Processing: The XA Specification.
- [11] https://github.com/keycloak/keycloak/issues/12400, Keycloak issue tracker. Issue #12400 “Clarify transaction-xa-enabled and add transaction-jta-enabled”.
- [12] https://github.com/cockroachdb/cockroach, CockroachDB database Github repository.
- [13] https://www.keycloak.org/docs/latest/server_development/index.html#cache-policies, Keycloak Server Development Guide, section “User Storage SPI”, subsection “Cache policies”.
- [14] https://www.keycloak.org/docs/latest/server_admin/#read_only_user_attributes, Keycloak Server Administration Guide, section “Mitigating Security Threats”, subsection “Read-only User Attributes”.
- [15] https://github.com/b1-systems/keycloak-user-storage-test, B1 Systems GmbH Github Repository “keycloak-user-storage-test”.
- [16] https://github.com/NovatecConsulting/keycloak-user-storage, Novatec Consulting GmbH. “keycloak-user-storage” Github project page.
- [17] https://www.keycloak.org/docs/latest/server_development/index.html#_user-storage-spi, Keycloak Server Development Guide, section “User Storage SPI”.
- [18] https://www.keycloak.org/docs-api/23.0.5/rest-api/index.html, Keycloak REST API Documentation Version 23.0.5.
- [19] https://www.keycloak.org/docs/latest/server_development/index.html#import-implementation-strategy, Keycloak Server Development Guide, section “User Storage SPI”, subsection “Import implementation strategy”.
- [20] https://github.com/keycloak/keycloak/security/advisories/GHSA-5q66-v53q-pm35, Github Security Advisory GHSA-5q66-v53q-pm35 “Plaintext Storage of User Password”.
- [21] https://www.keycloak.org/2022/07/storage-map.html, Keycloak Blog. New storage in Keycloak. July 27 2022 by Hynek Mlnařík.
- [22] https://www.keycloak.org/2023/10/map-store-removal, Keycloak Blog. Announcement: Discontinuation of Keycloak’s Map Store. October 17 2023 by Stefan Guilhen.
- [23] https://github.com/keycloak/keycloak/issues/12495, Keycloak issue tracker. Issue #12495 “Remove two ways for setting user fields in physical layer”.
- [24] https://developer.okta.com/docs/concepts/user-profiles/, Octa Inc. Developer Documentation. Section “Concepts”, subsection “User profiles”.
- [25] https://learn.microsoft.com/en-us/windows-server/identity/ad-fs/technical-reference/the-role-of-attribute-stores, Microsoft Learn. AD FS technical reference, subsection “The role of attribute stores”.

